This post describes how we started, back in 2020, to build a foundation model for grocery consumption as a stepping stone toward a broader foundation model for payments, retail, and ultimately human behavior—what we call BehaviorGPT. We drew on the language modeling paradigm, treating each user's consumption history as a sequence of tokens to learn "the language of grocery consumption." Along the way, we trained on roughly 600M online actions and 15B offline purchases (all grocery-related), ultimately developing a 150M-parameter Transformer with architectural improvements to handle the nuances of this tokenization.
The results were notable:
- 10× improvement in recommendations over baseline,
- +9.4% conversion against RichRelevance search and +5.7% over Algolia,
- +2.2% sales in physical stores after using dense vectors of physical stores to dynamically assign assortments based on regional behavioral patterns.
1. Introduction
Foundation models—large models trained on massive datasets to learn general-purpose representations—have shown remarkable success in text, vision, and genomics. Their power lies in extracting rich abstractions from diverse data, before adapting to specific downstream tasks.
However, a major slice of modern human-generated data isn’t textual or visual at all—it's behavioral. Every day, billions of people create chronological “trails” of discrete actions: transactions, searches, clicks, workforce logs, etc. We see a clear opportunity to model these sequences of actions at scale as the next frontier for foundational AI.
In language modeling, a model learns the probabilities of words (tokens) in a sequence, capturing linguistic and contextual relationships to predict future words. We extend this approach to behavioral data: for instance, user sessions on a retail platform or sequences of payment transactions. By adopting the “next event prediction” paradigm, we can learn powerful representations of both agents (the users) and items or services (the objects of interaction).
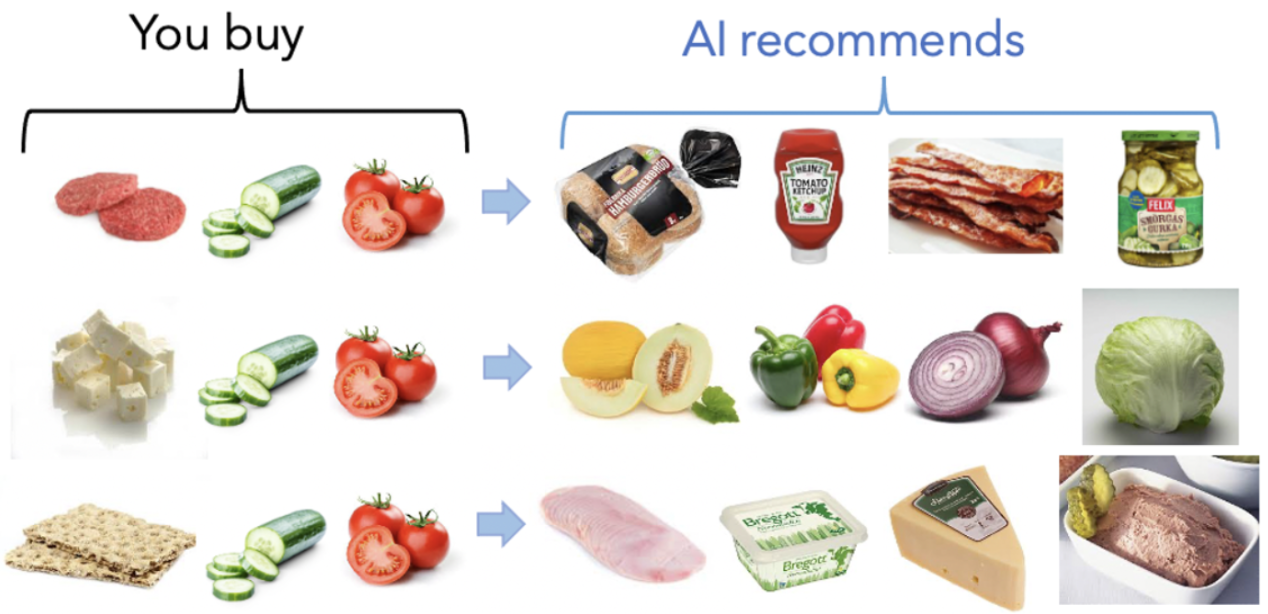
Personalization has always been key to higher customer engagement. Accurately predicting the next product or interaction is akin to how large language models “keep track of your conversation’s context.” In , we see examples of how a single tweak in the third-to-last product drastically changes a grocery recommendation, pivoting from hamburgers to salads or to a Swedish breakfast. This ability to present the right product to the right customer at the right time is the core intelligence for anyone selling products. This intelligence also supports search, recommendations, fraud detection, and business intelligence.
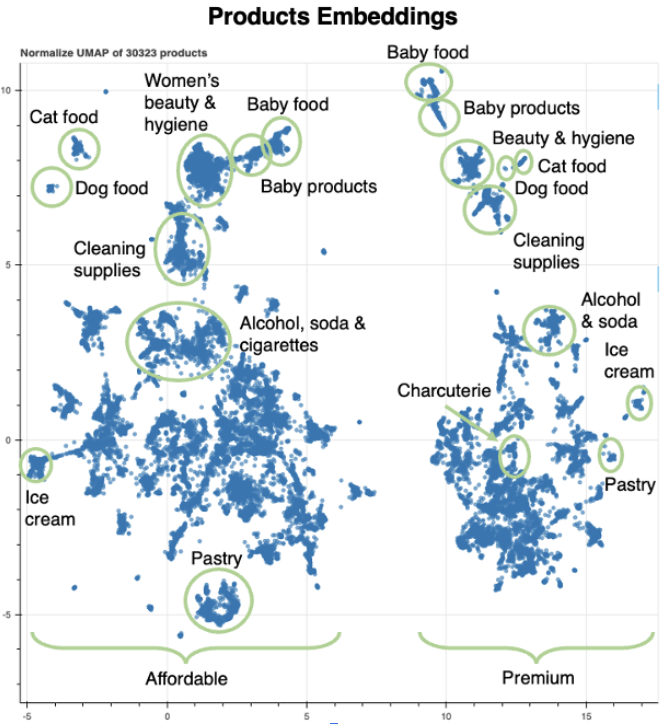
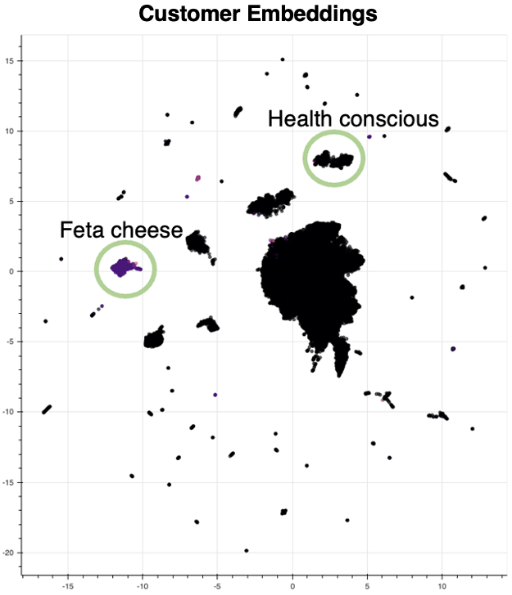
We chose groceries as our starting point because grocery data is incredibly rich: people purchase groceries 10× more frequently (roughly ten times as many pieces as clothing and twenty times as many personal-care products, per the BLS Consumer Expenditure Survey) than other product categories, and they typically return to the same stores. This frequency and consistency provide unusually thick transaction sequences. It gives us deep insight into an individual’s preferences, spanning myriad product categories. Our analysis even uncovered sensitive but telling behavior clusters—like a cohort associated with women on their period—which is simultaneously unsettling and fascinating. We also spotted other specific segments, like a growing health-conscious group and a frequent “feta cheese” cluster—both of which a leading consulting firm missed in a study for the same retailer.
2. Iterations
2.1 One-Hot Embeddings and Domains
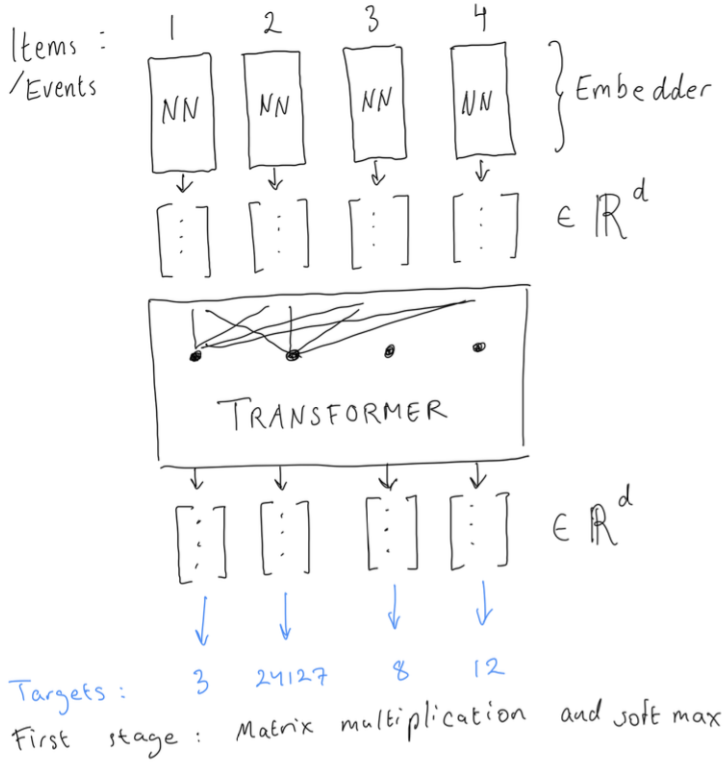
Our initial approach was straightforward: treat each product as a unique token and apply a causal language modeling scheme to predict the next product based on past products in the sequence—see for an architectural sketch. However, since we also get multiple pieces of contextual information when a user visits (e.g., region, date, device, demographics), we introduced domain embeddings for these factors. We concatenated these domain tokens with each product token embedding in the sequence.
We measured performance using “CartMetric”—the accuracy of predicting an item that actually appeared in the user’s next cart, given previous carts. Adding domain tokens improved our test-set CartMetric from 35% to 38.6% (a 10.3% improvement), especially for shorter sequences and cold-start situations. Further analysis revealed date/time (month, day of week) was most impactful, followed by region, then device.
Compared to a company baseline that simply recommended each user’s most frequently clicked item, our model delivered a 10.5× lift in recommendation conversion. We also leveraged it for search by combining our model’s probability scores with a simple Elasticsearch mechanism, which outperformed RichRelevance by 9.4%.
2.2 MLM on Text Descriptions
As we moved on to include 15B offline transactions spanning 1M unique events, having a 1M-sized output softmax layer became expensive. Moreover, offline and online product IDs didn't match across regions. So, we shifted to using product descriptions for identification, resulting in a reduced vocabulary of approximately 50K tokens.
We tried a Masked Language Modeling (MLM) approach, illustrating with a tiny two-item example:
pasta 1kg, barilla, $7.3 <sep> rao's tomato basil sauce, $6.8 <sep>We tested:
- Random Masking: Standard MLM.
- Mask All Text for a Single Product: Instead of partially masking a product, we masked its entire description at once.
The second strategy worked better, leading to behavior-driven embeddings that grouped together products commonly bought together, even if their descriptions varied. The idea was that "meaning is defined by the company it keeps," and here we want the "company" to be co-purchased items rather than lexical similarity in the product name.
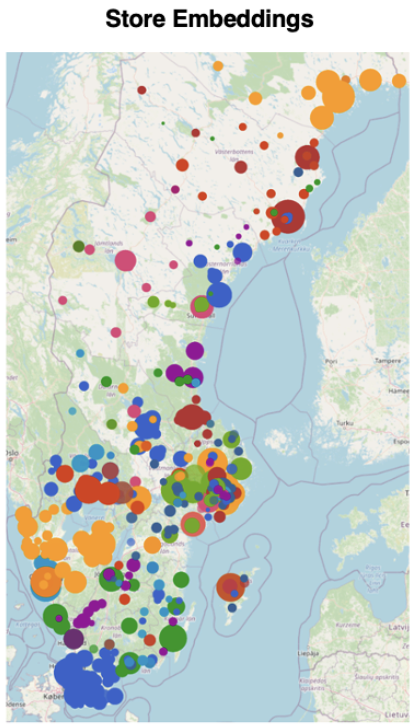
These learned embeddings were used to cluster stores and enable dynamic assortment assignments based on regional behavioral patterns, boosting physical store sales by 2.2%. See , for the colored clusters of store embeddings across Sweden.
2.3 End-to-End Image, Text, and Product Embeddings
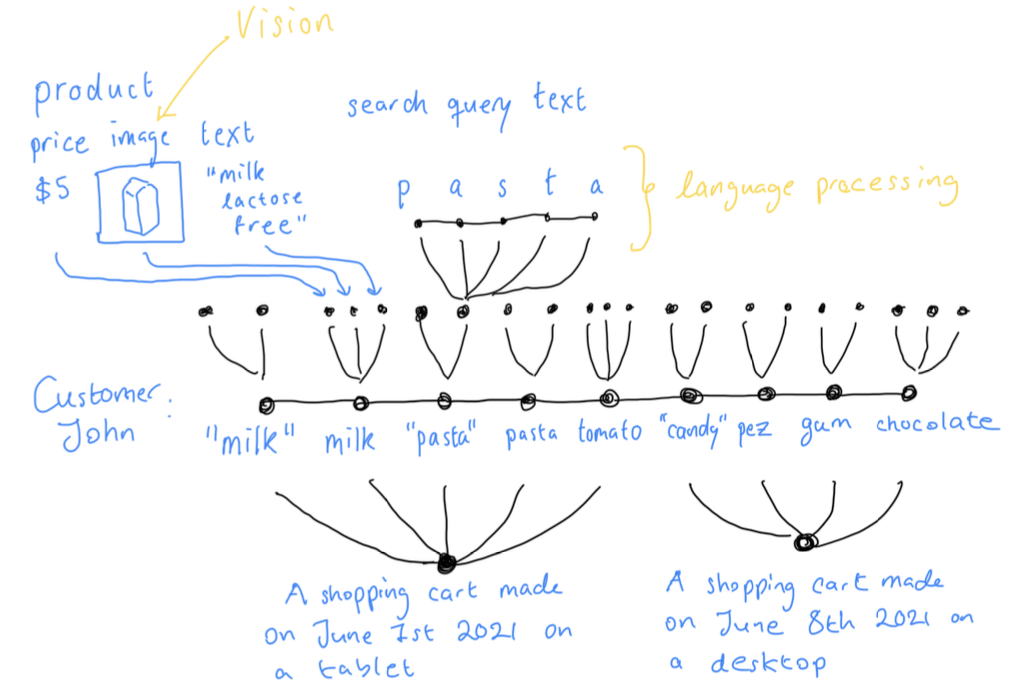
We wanted to handle multiple data sources (images, text, and more) seamlessly, including user searches. Since we can’t enumerate every possible user query as a token, we needed a flexible model that understands items from their text, visuals, and historical context—and also generalizes to unseen products.
In , you can see the full data with images, text, etc. We want to use vision to interpret images and language processing to understand text, ideally end-to-end so we learn these features based on behavior rather than other semantic aspects.
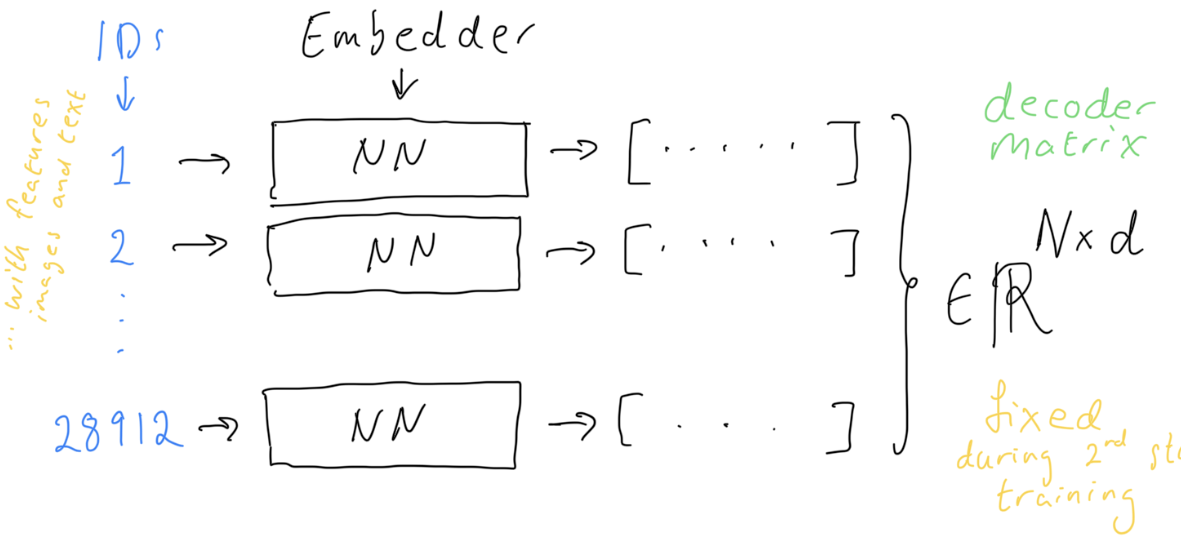
Our solution was to replace the simple one-hot embedder with a feature-embedder that ingests text and image features and outputs a dense vector. We then trained in two stages:
- Stage 1: Train a product embedder for the input events, together with the Transformer “contextualizer” in the middle, but with a large output matrix for the 1M+ products as tokens.
- Stage 2: Freeze or partially freeze that embedder, cache the embeddings, and train the main Transformer (the “contextualizer”) to predict which product comes next, given the stacked cached embeddings as targets. See .
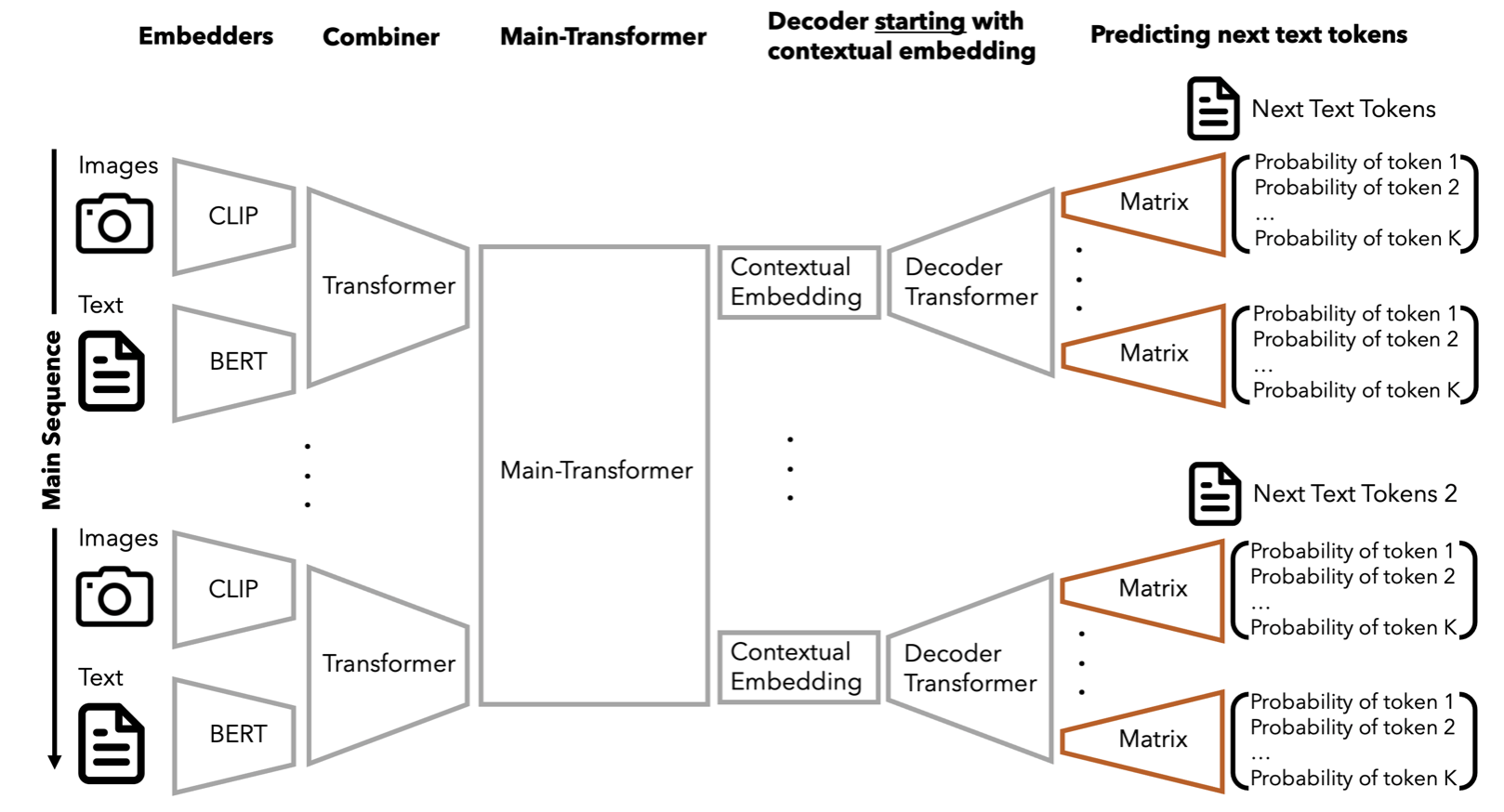
For input features, this approach is efficient because there are fewer events in the input than candidate events—particularly when using the traditional method of computing distributions over an entire assortment (e.g., 1M possible events). However, we shifted from training embeddings exclusively on inputs to jointly training an embedder on both inputs and outputs, employing smart sampling of candidates. Subsequently, we fine-tuned the model with the embedder frozen. Additionally, we introduced a decoder approach that predicts the text (and other features) of the next event instead of merely retrieving it, enabling more generative capabilities—see .
Including text and images allowed the model to discover behavioral similarities more efficiently. It proved especially critical for search, where user queries are short and brand-specific. We found that training the tokenizer and text embedder directly on the sequence task (rather than a general-purpose autoencoder) was vital—likely because grocery consumption has a very domain-specific "language."
This approach handily beat Algolia by 5.7% and Loop54 by 7.5% (two commonly used search-tools) in conversion, despite both solutions relying on considerable manual tagging. Our new model also produced search term suggestions that increased interactions by 49.1%. As a recommendation bar, it achieved a 54% conversion rate—reflecting the system's deep personalization. Additionally, we benchmarked this search against text and sentence embedders, which simply did not stand a chance.
It’s also worth noting that we're modeling a probability distribution p(sequence of behaviors), representing how likely a given sequence of user behaviors is. This enables us to detect fraud by identifying sequences of behavior that are highly improbable. For instance, during self-checkout, if someone buys almost all the ingredients for a dish but omits just one, we can flag this as potentially suspicious—suggesting that item may have been intentionally unpaid. We found this approach more effective than simply using dense semantic transaction vectors or embeddings.
3. Qualitative Intelligence: Taco, "Fredagsmys," and Seasonality
The intelligence of this model was astounding. Trained mainly on the Swedish market, it captured Swedish consumption patterns with surprising fidelity.
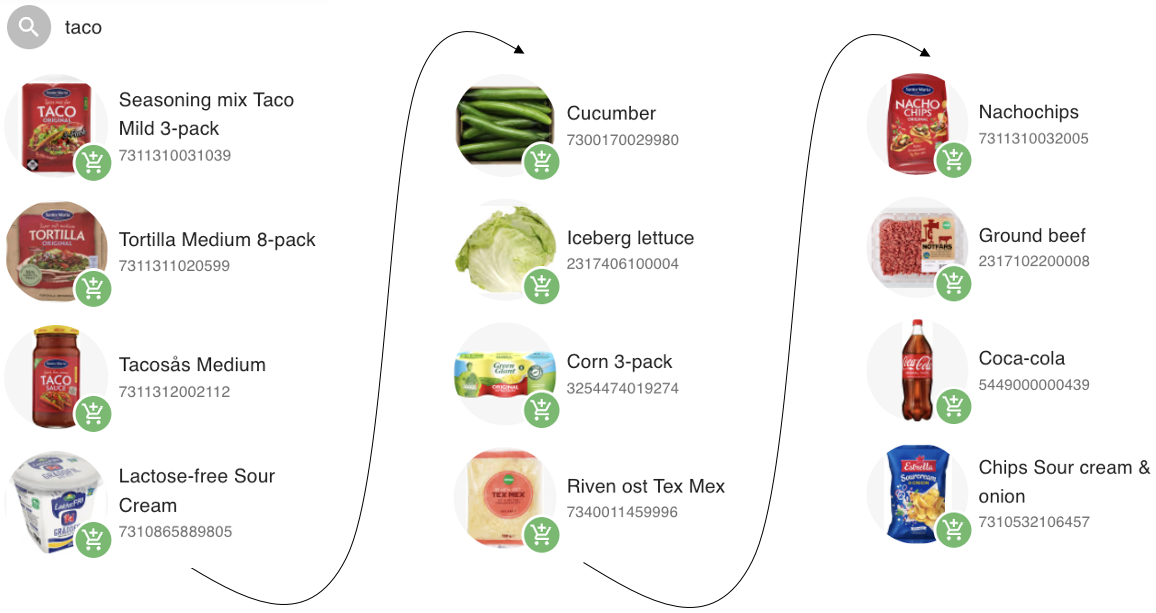
In , you can see the output from simply searching "taco" and then clicking "next" on the recommended item each time. The model assembles a full Swedish taco meal, complete with chips and Coke. If you already had organic items in your basket, it would swap in organic versions seamlessly.
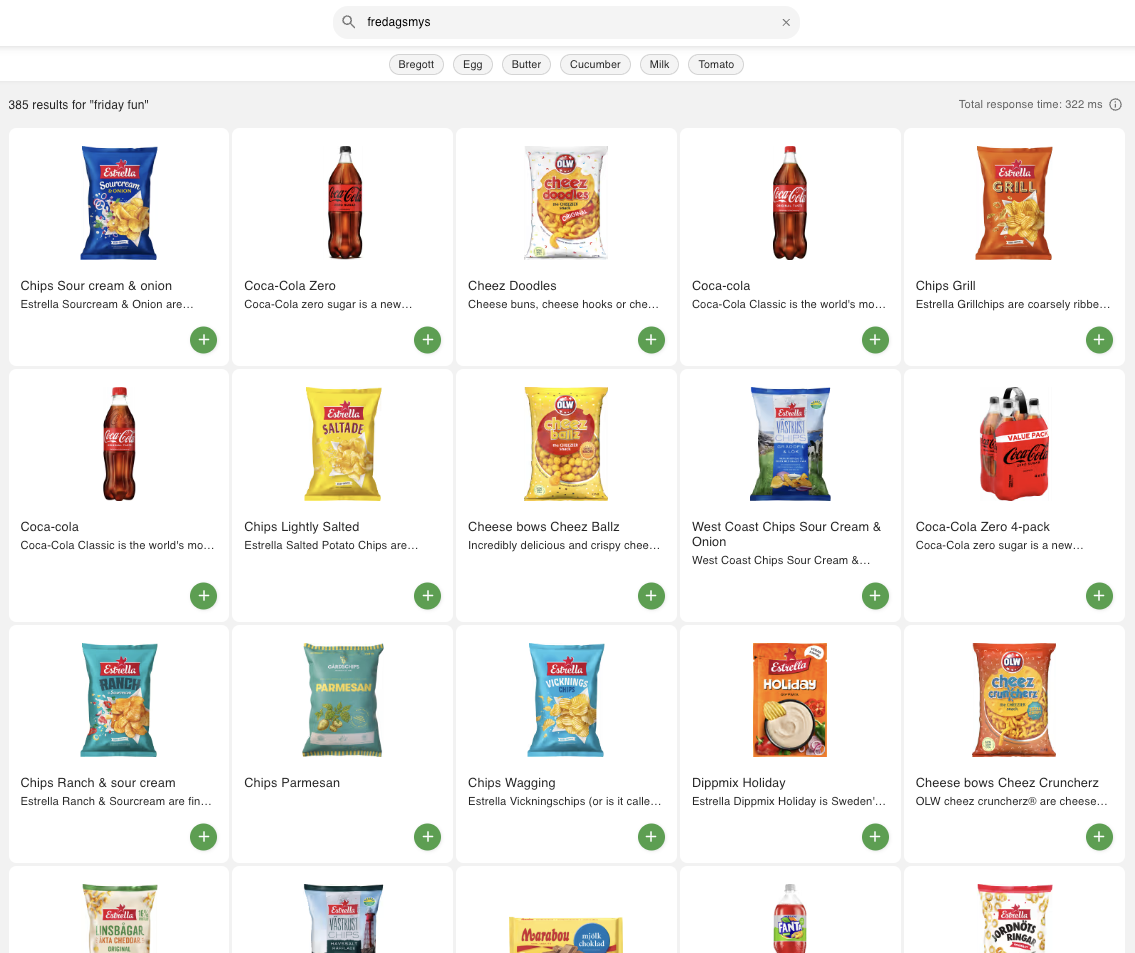
The model also captures abstract and idiosyncratic expressions, like "fredagsmys" (a Swedish phrase for a cozy Friday night at home, typically with candy, soda, and a movie). In , you see results that perfectly match this tradition—setting a new standard for the industry.

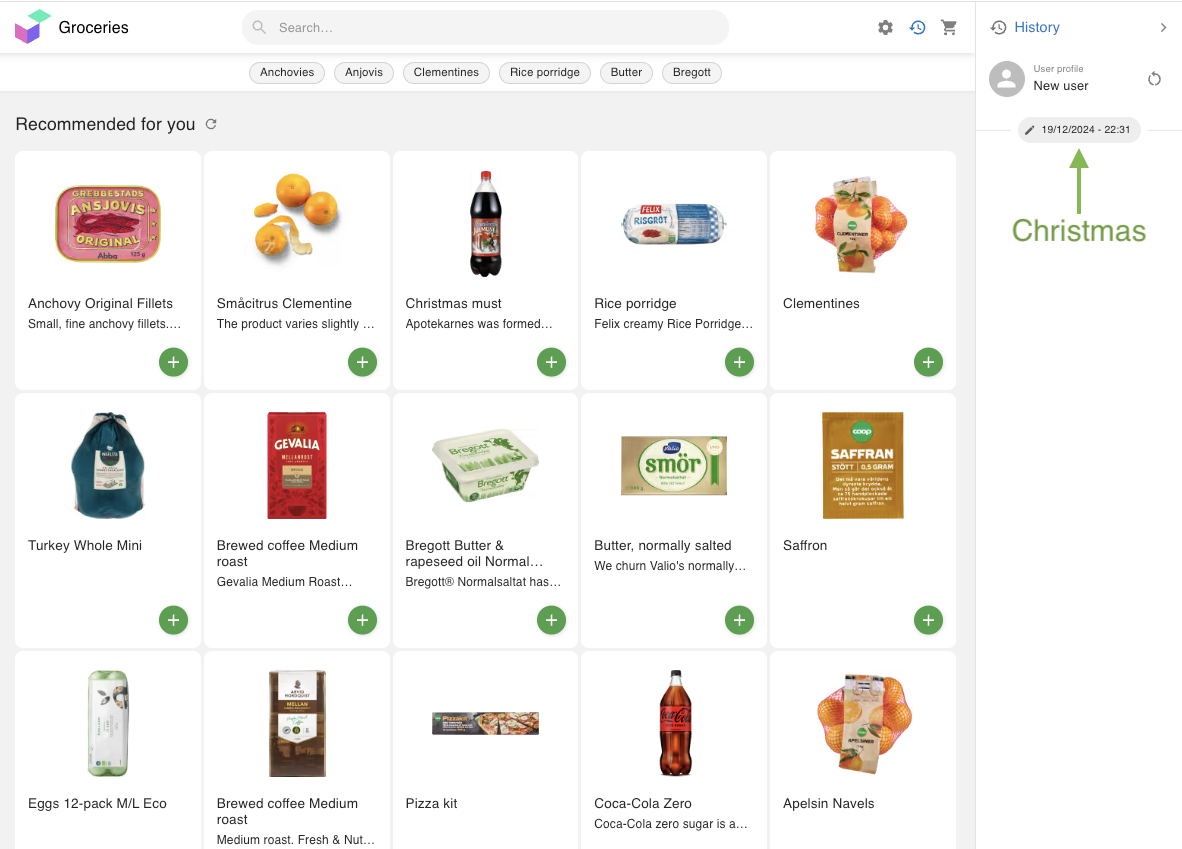
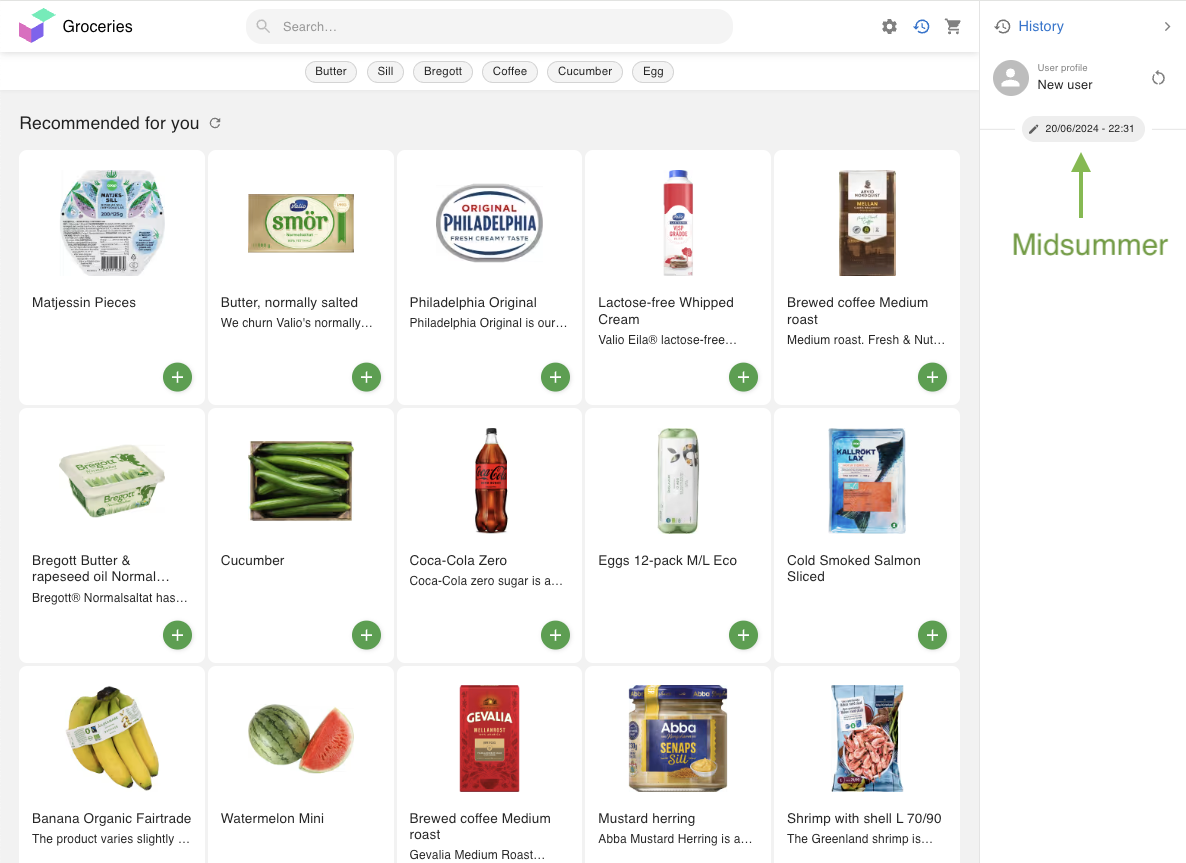
Domains proved highly useful for time-dependent nuances. In , you can see how the model's outputs change from just before Christmas to the Swedish summer holiday, Midsummer. Of course, it adapts daily throughout the year, but these occasions highlight clear seasonal shifts. Previously, manual teams had to configure such seasonal results—costly and time-intensive. Now, the data itself handles these transitions automatically, shaping not only the landing pages but all subsequent search and recommendation results.
4. Discussion
In 2020-2021, we built this Foundation Model for Grocery Consumption—the inception of BehaviorGPT, now a leading foundation model for payments and retail. Long before "foundation models" and "ChatGPT" became common terms, we showed that scaling laws and transformer-based architectures apply powerfully to behavioral data. The results outperformed incumbent solutions and added real value to retailers.
Looking back, key takeaways include:
- Treating user actions like tokens in a language model offers strong performance on recommendation, search, and beyond.
- Domain embeddings (date/time, region, device) help with seasonality and localization.
- Text/image-based embeddings unify offline, online, and newly introduced products under the same model, and should be trained end-to-end on the sequential task.
BehaviorGPT not only improves user experience (recommendations, search) but also helps with fraud detection, store assortment, and deeper business intelligence.
We have come a long way since then. Our follow-up work scales these ideas further, covering broader retail catalogs and leveraging real-time streaming data. But the foundations we laid here—viewing action data as a language—remain at the core of how BehaviorGPT continues to evolve.
Thank you for reading! We hope this overview demonstrates the power of foundation models on behavioral data—and how groceries, rich with frequent purchases and cultural nuances, served as the perfect proving ground for BehaviorGPT.
We will soon release a technical post detailing how we've expanded BehaviorGPT into a foundation model covering workforce dynamics (employee behavior), aesthetics and art, and ultimately a wide range of discrete behavioral and transactional action spaces—now training on trillions of real-world actions. We call this latest iteration BehaviorGPT-r3 and will be providing increased open access to it. Stay tuned and make sure to follow us!
Would you like to try BehaviorGPT when it's released to the public?
Join the waitlist5. References
The work described here was done between 2020 and 2021. Original source documents are linked below.
- October 2020 pitch deck — our original vision for modelling behaviour, transactions, and retail with language-model techniques.
- June 2021 data & model sketches — a outline of the data pipeline and modelling approach.
Citation
@article{unbox2025behaviorgpt,
author = {Br{\"u}el Gabrielsson, Rickard and others},
title = {A Foundation Model for Consumption, Transactions, and Actions: The Inception of BehaviorGPT},
journal = {Unbox AI Blog},
year = {2025},
month = may,
url = {https://research.unboxai.com/foundation-model-for-consumption-transactions-and-actions.html},
}